Mit SFDX hat Salesforce einen tollen Open Source Toolstack für die professionelle Entwicklung auf Ihrer Plattform mit gebracht: SFDX CLI, SFDX Plugins, Visual Studio Code, VS Code Extension Pack, Lightning Web Components und natürlich Git mit seinem eigenen Ökosystem.
Die Möglichkeiten, die wir Entwickler damit haben, sind gigantisch, und ich bin der Überzeugung, dass es nicht nur ein richtiger Schritt in die richtige Richtung ist, sondern für den langfristigen Erfolg von Enterprise Software eine absolute Notwendigkeit ist. Aber das ist ein Thema für einen anderen Blog Artikel. Denn heute möchte ich mich mit der Komplexität dieses Toolstacks beschäftigen: Je flexibler die Tools und der Toolstack, desto mehr Wissen müssen Anwender (in diesem Fall: wir Entwickler) mitbringen, um sie effizient und effektiv einzusetzen. Und genau da liegt auch der Hase im Pfeffer: Es gibt mit Trailhead zwar eine Schulungsplattform für Administratoren und Business User und mit Salesforce Stackexchange auch eine tolle Community für Entwickler, aber ich habe bisher leider keine guten Ressourcen (Lehrmaterial) gefunden, die sich in Tiefe mit den organisatorischen und prozessualen Aspekten von SFDX auseinander setzen.
Auch auf die Gefahr hin, hier vielleicht die ein oder andere gute Quelle übersehen zu haben, möchte ich genau diese Lücke füllen: In diesem Artikel möchte ich mich vor allem mit der Skalierung von SFDX auseinander setzen: Wie organisiert man Source in SFDX und wie skaliert man prozessual von einem 1-Mann-Team zu einer großen Operation mit einer potenziell zweistelligen Anzahl an Entwicklern?
Ich versuche dabei, möglichst analytisch vorzugehen und entwickle ein modulares, ganzheitliches und skalierbares Konzept:
- Analytisch: Die einzelnen Überlegungen sollen nachvollziehbar sein und auf die individuelle Situation des Lesers angepasst und übertragen werden können.
- Modular: Das Konzept soll auch in einzelnen Teilen bzw. Aspekten anwendbar sein.
- Ganzheitlich: Das Konzept soll den gesamten Entwicklungs-Prozess unterstützen.
- Skalierbar: Das Konzept soll für kleine wie große Teams und bei simplen und komplexen Projekten anwendbar sein.
Aber eines nach dem anderen: Beginnen wir mit den Anforderungen an Source Code Management mit SFDX. Auch wenn ich diesen Post mit Unlocked Packages im Hinterkopf schreibe, sind viele Konzepte für 2nd-gen Managed Packages anwendbar.
Übersicht
Aufgrund seiner Komplexität möchte ich das Thema in mehrere Einzelposts aufteilen. In diesem Post versuche ich, die grundlegenden Anforderungen an Source Code Organisation und damit einhergehend die grundlegenden Probleme, vor denen Entwickler Teams stehen, zu identifizieren. Im zweiten Post werde ich die so formulierten Anforderungen und Überlegungen in die Praxis übertragen und meinen best practice vorstellen, das 1:1:1 Setup. Zum Abschluss zeige ich in einer Case Study eine CI/CD Implementierung basierend auf dem 1:1:1 Setup bei TMH (The Mobility House) vor.
- Teil 1: Anforderungen und Konzept (dieser Post)
- Teil 2: Ordnerstruktur und Prozesse mit dem 1:1:1 Template
- Teil 3: Continuous Integration mit CircleCI
Organisation von Source
Die Ziele einer guten Source Code Management Strategie sind praktisch immer die gleichen, egal auf welcher Plattform bzw. welchem Technologie Stack man arbeitet: Reduktion der Komplexität (Isolieren von Abhängigkeiten, Aufteilen von Verantwortlichkeiten, usw), Nachvollziehbarkeit aller Änderungen (Commit History), Qualitätssicherung (Branching Strategien, Code Reviews) und Skalierbarkeit (Branching- und Merging Strategien, Automatisierung).
Diese Ziele gelten natürlich auch für Salesforce, und ich möchte zeigen, wie SFDX bei der Umsetzung der Ziele eingesetzt werden kann. SFDX bietet uns dazu drei grundlegende Abstraktionsebenen: Package, SFDX Project und Repository. Auf jeder dieser Ebenen werden wir unterschiedliche Probleme lösen und entsprechend unterschiedliche Ziele optimieren.
Package
Ein Package ist das kleinste, in sich geschlossene Artefakt einer Salesforce Org. Es kann dabei vom eigenen Team entwickelt werden oder aus einer fremden Quelle (z.B. Open Source oder von einem externen Team) bezogen werden. Wir werden gleich sehen, warum es wichtig ist, die Begrifflichkeiten Package und SFDX Projekt sauber voneinander zu trennen.
Scope
Auf der Package Ebene kümmern wir uns im Grunde um den inhaltlichen Funktionsumfang, den wir als Artefakt ausliefern und strukturieren und wir organisieren den Status quo der Metadaten (Objekte, Custom Fields, Apex Klassen, usw) für diese Funktionalität.
Somit schaffen wir vor allem Übersicht über unseren Source und legen einige Grundlagen für eine saubere Arbeit mit SFDX Projects und unserem VCS. Die Entscheidungen, die auf dieser Ebene getroffen werden, spielen eine große Rolle für die spätere Skalierbarkeit in umfangreichen Projekten und größeren Teams. Das Package ist die mit Abstand wichtigste Komponente unserer Strategie, um Komplexität effektiv zu reduzieren: Nur wenn wir hier eine intelligente Ordnerstruktur wählen, werden wir dauerhaft Übersicht behalten und Merge Konflikte minimieren können.
Anforderungen
Daraus ergeben sich eine Reihe von Anforderungen, denen die Ordnerstrukturen eines Packages gerecht werden müssen:
- Der Source Code soll möglichst unkompliziert und intuitiv organisiert sein. Vor allem neue Entwickler sollen sich schnell zurecht finden und sich bei großen Projekten nicht durch Ordner mit 100ten von Apex-Klassen oder 1000en Custom Metadata Type Records wühlen müssen.
- Die App bzw. das Package soll leicht um neue Features erweitert werden können. Die Ordnerstruktur muss die typischen branching Strategien gängiger VCS unterstützen um z.B. Mergekonflikte zu minimieren.
- Ergänzend sollte es die Ordnerstruktur auch ermöglichen, an unabhängigen Features (des selben Packages) auch unabhängig voneinander arbeiten zu können.
- Die Ordnerstruktur muss es ermöglichen, Layouts, Flexipages, „Test“ – Custom Metadata Type Records oder ähnliches, was zwar nicht ins Package gehört aber auf der Scratch Org verfügbar sein soll, hinzufügen zu können.
- Genauso muss Metadata verwaltet werden können, die zwangsläufig deployed werden muss (z.B. Queues mit Membern oder Workflow Email Alerts mit Organisation Wide Addresses als Absender)
- Zu guter Letzt soll das Template so generisch sein, dass es ohne strukturelle Anpassungen für neue Packages kopiert werden kann. Das wird vor allem für Automatisierung und CI/CD Pipelines wichtig.
Typische Fehler
Die häufigsten Fehler, die ich in meiner Berufslaufbahn immer wieder gesehen habe, lassen sich grob in 3 Gruppen unterteilen.
Der gesamte Source ist in einer force-app/main/default-Struktur
Ich durfte über den Sommer 2019 einige Monate an einem Angebotstool eines großen Verlagshauses mitarbeiten. Das gesamte Tool hatte neben einer durchaus komplexen UI auch eine ganze Menge von Apex Klassen. Bestimmt im niedrigen dreistelligen Bereich, zusammen mit den meta.xml-files aber dennoch einige Hundert Dateien. Alle im selben classes Ordner. Überflüssig zu erwähnen, wie schwer es unter diesem Umständen ist, eine bestimmte Klasse wieder zu finden bzw. sich nur einen Überblick über die Features und den dafür zuständigen Code zu verschaffen.
Dateisystem Ordner sind dafür da, inhaltlich zusammengehörende Metadaten (Apex Klassen, Aura/LWC Komponenten, Visualforce Seiten, usw) zu gruppieren.
Große Packages mit zu vielen Features
Die Diskussion über optimale Dekomposition wird wohl auch auf absehbare Zeit noch kontrovers geführt werden. Mir passiert es immer noch regelmäßig, dass ich an einem Package arbeite, dort ein neues Feature einführe und zu spät merke, dass dieses Feature von der Komplexität wohl besser ein eigenes Package hätte sein sollen. Das Ergebnis ist dann in der Regel ein Package mit voneinander unabhängigen Funktionalitäten, die nicht selten sogar unabhängig voneinander weiter entwickelt werden. Spätestens wenn man in einem Release nur ein Feature weiterentwickelt, das kaum Bezug zu einer anderen Funktion hat, sollte man darüber nachdenken, das Package in mehrere kleinere Packages zu zerteilen.
Enterprise Architektur Muster, die Dekomposition unmöglich machen
Anders als bei einem klassischen Monolithen oder der happy soup of metadata, wie sie von Salesforce liebevoll genannt wird, kann man in einem modularen, package-basierten Entwicklungsprozess nicht ohne sorgfältige Planung und Umsetzung neue Zwischenabstraktionsschichten oder Frameworks einsetzen. Viele der sogenannten „Enterprise Architektur Muster“ verletzen z.B. die SOLID Prinzipien der Objektorientierung, einfach weil sie aus einer Zeit kommen, als man sich über Abhängigkeiten noch keine Gedanken gemacht hatte. Ein typisches Beispiel sind Trigger Frameworks, in denen der Dispatcher alle Handler im Vorfeld kennen muss. Damit ist ausgeschlossen, dass dieses Framework in einem eigenständigen Package als Abhängigkeit entwickelt werden kann. Wie man das Konzept von dependency inversion für solche Frameworks mit Custom Metadata Types dennoch umsetzen kann, würde den Rahmen hier jedoch sprengen.
Immer wieder habe ich in der Vergangenheit Projekte gesehen, in denen veraltete „Enterprise Patterns“ eingesetzt wurden, die eine Dekomposition der Org in einzelne Packages ohne komplette Neuimplementierung unmöglich gemacht haben. Frameworks sind nutzlos, wenn man sie nicht als Abhängigkeit entwickeln und einsetzen kann.
SFDX Project
Das SFDX Project ist technisch gesehen eine Ordnerstruktur mit Konfigurationsdateien, die der CLI sagt, was sie tun soll. Obligatorisch ist das sfdx-project.json, in der Source Ordner mit Package Content definiert werden und lokale Aliase für Package Ids bzw. Subscriber Package Version Ids verwaltet werden.
Scope
Aber kurz zurück zum Konzept eines SFDX Projects und welche Probleme wir auf dieser Ebene lösen: Hier konfigurieren wir unsere Scratch Org, kümmern uns um die Development Automation (Scratch Org Setup und Tear Down Scripte, Test Daten, etc) und –das wichtigste überhaupt– Versionieren das Package und definieren seine Abhängigkeiten.
Anforderungen
Damit ergeben sich für ein SFDX Project die folgenden simplen, aber elementaren Anforderungen:
- Es muss sichergestellt sein, dass ausschließlich der aktive Source (d.h. das Package, an dem wir tatsächlich arbeiten) in source tracking ist und wir unsere Abhängigkeiten in einer fixen Version (wie in der
sfdx-project.jsondefiniert) auch auf der Scratch Org installieren. - Build, Setup und Deployment Scripte sowie Test Daten müssen auf das zu entwickelnde Package abgestimmt werden können. Der gesamte Setup soll vollautomatisert werden können.
- Das
sfdx-project.jsonsoll möglichst übersichtlich sein und dem Entwickler z.B. schnell zeigen können, welcher Build welcher Version gerade der aktuellste ist oder welche Aliase existieren. Außerdem möchten wir Mergekonflikte so gut es geht vermeiden, gerade wenn wir in großen Teams mit mehreren Entwicklern arbeiten. - Analog zum Package brauchen wir auch auf dem SFDX Project eine einheitlich replizierbare Struktur, um beim Setup eines neuen Projects möglichst viel wiederverwenden zu können z.B. mit Templates zu arbeiten.
Diese Anforderungen bringen uns zu der Bedeutung der ersten beiden „1“ meines 1:1:1 Setups: Jedes Package ist alleine in seinem eigenen SFDX Project und ein Project hat nur exakt ein Package.
Typische Fehler
Die typischen Fehler im Setup von SFDX Projects lassen sich in der Regel auf die hohe Flexibilität zurückführen und in 2 Gruppen unterteilen.
Dependencies sind als Source im selben SFDX Project
Theoretisch kann man über die sfdx-project.json beliebige Ordner als „source folder“ definieren, selbst wenn diese nicht als eigenes Package behandelt werden. Da die CLI nativ noch keine Möglichkeit bietet, Abhängigkeiten beim Scratch Org Setup automatisch zu installieren, ist es natürlich naheliegend, alle Abhängigkeiten des Packages direkt irgendwo im selben Project zu haben und einfach mit force:source:push mit zu pushen. Das ist im allgemeinen Entwicklungsworkflow nicht nur deutlich langsamer, sondern begünstigt bad practices wie die gleichzeitige Arbeit an Dependencies während eigentlich an einem anderen Package gearbeitet werden soll. Dazu hat die CLI zum jetzigen Stand (Juni 2020) noch einige Einschränkungen, sodass z.B. bei mehreren Source Ordner mit Custom Labels oder Custom Fields für die selben Objekte nicht gleichzeitig gepusht werden können.
Stattdessen sollten Abhängigkeiten entweder über ein Bash/PowerShell Script beim Scratch Org Setup installiert werden oder man installiert sich z.B. Texei’s SFDX CLI Plugin, das mit texei:package:dependencies:install genau den richtigen Befehl mitbringt. Dieser Ansatz funktioniert wiederum am besten, wenn jedes Project nur exakt ein Package hat, da die zu installierenden Abhängigkeiten dann einfacher automatisch zu identifizieren sind und Setup Scripte leichter für neue Packages angepasst werden können.
Mehrere Packages in einem Projekt
SFDX gibt uns die Möglichkeit, in der sfdx-project.json beliebig viele Packages in einer flexiblen Ordnerstruktur zu konfigurieren. Und auch ich bin Anfangs der Versuchung verfallen und habe mehr als 10 Packages in meiner ersten größeren Org im selben SFDX Project verwaltet. Die Probleme liegen auf der Hand: Bei paraleller Arbeit an mehreren Packages (egal ob alleine oder durch mehrere Entwickler), gehen alle neue Package Versionen in die selbe sfdx-project.json. Dadurch sind Merge-Konflikte praktisch vorprogrammiert, insbesondere bei ausgereifteren CI/CD-Pipelines, die bis zum Package Build und Install auf Staging automatisieren.
Ein solcher Setup macht es unheimlich schwer, bestehende Scripte, Testdaten und Konfigurationen für neue Projekte, die ggf. unabhängig entwickelt werden sollen wieder zu verwenden. Als Grundlage für Automatisierung und vor allem Skalierung empfiehlt es sich also unbedingt, ein SFDX Project auf exakt ein Package zu beschränken. Durch eine standardisierte Ordnerstruktur ist gewährleistet, dass Build und Deployment Scripte mit sehr wenig Aufwand für neue Packages angepasst werden können und neue Packages modular mit wenig Aufwand in eine CI/CD Pipeline integriert werden können.
Source Control bzw. Repository
Das tolle an SFDX ist die Flexibilität, die dem Entwickler bei der Wahl seines Toolstacks gelassen wird. Visual Studio Code unterstützt neben Git eine Vielzahl von Source Control Providern. Git wiederum bietet eine Vielzahl von Hostern wie GitHub, GitLab oder Bitbucket und CI/CD Provider wie GitLab Pipelines, Bitbucket Pipelines, GitHub Actions, CircleCI und viele mehr. Ich persönlich arbeite mit Git und GitHub, die Erkenntnisse und Aussagen sollten jedoch auf andere Version Control Toolstacks übertragbar sein.
Scope
Im Version Control System steuern wir im Grunde die wichtigsten Faktoren überhaupt: Berechtigungen (Zugriff auf den Source), Automation und Skalierung. Erst mit einer durchdachten Project/Package Struktur ist ein distributed VCS wie Git in der Lage, sein volles Potenzial auszuschöpfen.
Anforderungen
Damit Git zusammen mit SFDX richtig funktionieren kann, sollte man folgendes beachten:
- Zugriff auf den Source nach dem „need to know“ – Prinzip: Externe Dienstleister, die mit der Entwicklung einer eigenen App (Package) beauftragt werden, sollen nicht zwangsläufig Zugriff auf den gesamten Source brauchen.
- Eine saubere Commit History, die selbst bei sehr großen Teams und vielen Packages überschaubar und strukturiert bleibt.
- Commits zu einem Feature bzw. einer Package Version sollten nach einem Merge bereits zusammen in der Historie auftauchen und nicht erst mit
rebaseundcherry picknachträglich aufgeräumt und zusammengefasst werden müssen. - Einfaches Ausgliedern von neuen Abhängigkeiten (falls die Komplexität in einem Package zu groß wurde) bzw. Aufsetzen von neuen Packages oder Einbindungen von externem Packages in die Operation.
- Skalierbare Performance, die selbst mit vielen Media Dateien und und großen Teams nicht einbricht.
All diese Anforderungen stoßen einen gerade zu auf die dritte „1“ im 1:1:1 Setup: Jedes SFDX Project ist ein (Git) Repository. Hat jedes Package sein eigenes (Git) Repository, sind sämtliche Commits einer Package Version komplett dort isoliert. Das vereinfacht die Nachvollziehbarkeit immens und gibt uns nebenbei noch die Möglichkeit, nur ganz punktuell Zugriff auf den Source zu gewähren.
Typische Fehler
Auch hier habe ich in der Vergangenheit immer wieder die selben Fehler gemacht oder bei anderen gesehen.
Der gesamte Source in einem Mono-Repo
Unabhängig davon, wie man nun seine Packages und SFDX Projects strukturiert, bin ich schon häufig mit gigantischen Mono-Repos konfrontiert werden, welche den gesamten Source Code einer Salesforce Org beinhalten. Sofern das Projekt noch relativ klein ist und keine relevante Menge an Media Daten beinhaltet, hat das zumindest keine negativen Auswirkungen auf die Performance. Ist aber z.B. ein Teil der Docu direkt im Repo (Pozil’s sfdc-ui-lookup-lwc oder mein partner-billing) oder haben wir große statische Resourcen, kann ein Repository schnell mal mehrere 100 MB erreichen. Und wie es um den Glasfaser Ausbau in Deutschland steht, wissen wir ja leider alle.
Da Repositories nie kleiner werden, macht es zwangsläufig Sinn für die Aufrechterhaltung der Performance zumindest bei neuen Packages mit einem frischen Repo ohne Altlasten zu starten. Ganz nebenbei lässt sich so auch verhindern, dass jeder Entwickler gleich kompletten Vollzugriff auf den gesamten Source Code bekommen muss.
Verzicht auf Submodules
Viele Entwickler haben Berührungsängste mit git submodules. Warum genau das so ist, kann ich nicht sagen, ich persönlich kann die Kritik ehrlich nicht nachvollziehen. Das Mehr an Übersicht und Strukturierung, seit ich in einem „Master Repository“ alle Packages als Submodules eingebunden habe, ist gigantisch. Jedes Production Release ist ein separater Commit des Submodule Updates, der dort auf den getaggten Merge-Commit (z.B. v0.2.0) im jeweiligen Repository des Packages verweist. So habe ich die Inhalte der einzelnen Releases sauber getrennt von der Gesamthistory der Org, in der konkret ersichtlich ist, welche Version wann auf Production installiert wurde. Dennoch kann ich mit git clone --recurse-submodules https://github.com/myusername/my-repo.git mit einem Befehl die gesamte Org auschecken – wenn ich die Berechtigung dazu habe.
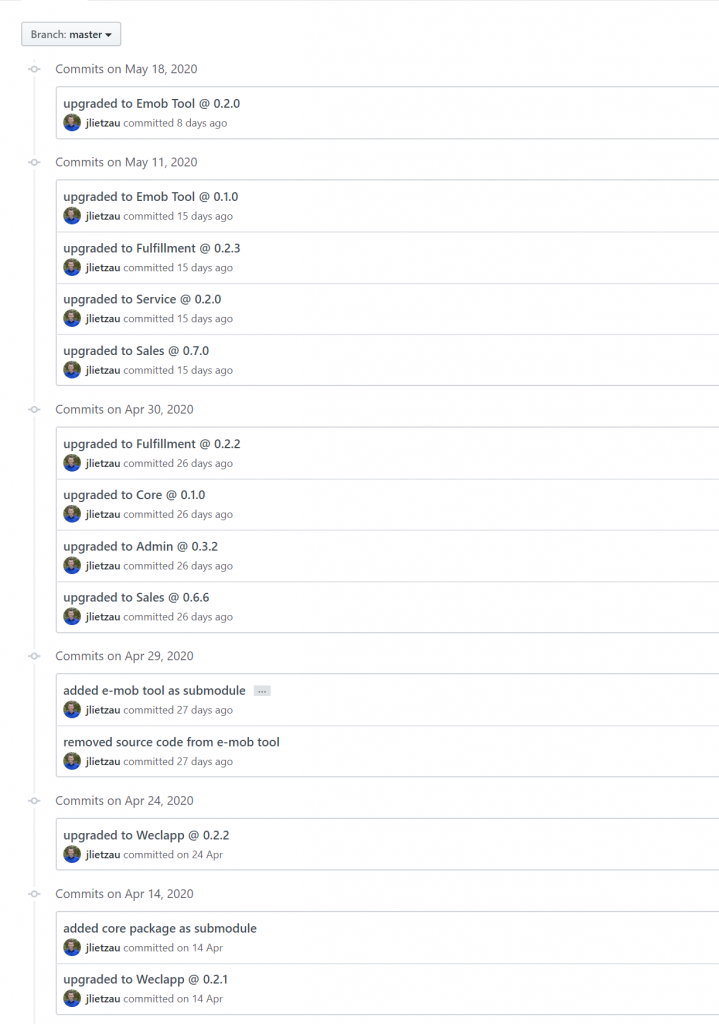
Da die einzelnen Package Repositories nur den Source eines einzigen Packages beinhalten, sind Tags und Releases angenehm aufgeräumt:
Weiterführende Gedanken
Das 1:1:1 Setup bedeutet also, exakt ein Package in einem SFDX Project in einem (Git) Repository. Bei TMH hat dieser Ansatz für uns die Komplexität massiv reduziert und mir viele Probleme erspart, die ich in der Vergangenheit in anderen Projekten erlebt habe. Zum Abschluss noch ein kleines Schaubild, wie die typische Ordnerstruktur eines klassischen working directory auf die 3 Ebenenen verteilt ist.

Im nächsten Post werde ich dieses Konzept in einem Template mit Beispielcontent umsetzen und zeigen, wie ein typischer Entwicklungsprozess vom ersten git checkout -b bis zum Release aussehen kann.